The Knuth-Bendix completion procedure (when it succeeds) transforms a collection of equations into a confluent, terminating rewrite system. Sometimes the procedure fails, and sometimes does not terminate, but The Handbook of Computational Group Theory by D Holt remarked that even in this case it generates an infinite set of rewrite rules that are complete, and An Introduction to Knuth-Bendix Completion by AJJ Dick also mentions that in the nonterminating case one can derive a semi-decision procedure. I naturally had to hack this up in Haskell, to create an infinite set of rewrite rules as a lazy list. This illustrates the very real software engineering benefit of decoupling creation and consumption of infinite data. As usual, this post is a valid literate Haskell file, so save it so something like KnuthBendix.lhs and compile with ghc --make KnuthBendix or load it up with ghci KnuthBendix.lhs
> module Main where
> import Control.Monad
> import Data.List
> import Test.QuickCheck hiding (trivial)To give a little background, something I realize I’ve neglected in the past, Knuth-Bendix completion is a technique in universal algebra, which is essentially the study of unityped syntax trees for operator/variable/constant expression languages, like these:
> data Term op a = Operator op [Term op a]
> | Variable String
> | Constant aYour usual algebraic structures are for the most part special cases in universal algebra – anything that has an ambient set with some bunch of operators and equational axioms qualifies, and universal algebra supplies the variables to represent unspecified quantities.
For example, a monoid is a set S with an operator * and a special constant e obeying these axioms, where x, y, z are variables that can be replaced by any term.
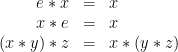
Aside: Consider the obvious way to axiomatize a group in this framework. I think it is a nice example of the interaction of constructive logic and computation.
But anyhow today I’m not going to use this structure because I can explain and explore Knuth-Bendix more quickly by sticking to monoids. The full completion procedure, and its modern enhancements, works on terms with variables and uses unification where I use equality, and superposition where I use string matching. In the case of a monoid, the associative law lets me simplify the term structure from a tree to just a list, and since I’m not including variables, I deal just with words over my alphabet a:
> type Word a = [a]A presentation is just a formalism as above, specifying the ambient set X (here, the type parameter a), and some equalities R called relations, written in mathematical notation as
⟨X ∣ R⟩
and in Haskell
> type Relation a = (Word a, Word a)
> type Presentation a = [Relation a]For an easy example of a monoid and its presentation, Bool forms a monoid using the && operator which has identity True. Here is a presentation for the monoid in each notation (in general, presentations are not unique, and there’s a whole theory of messing about with them, which is exactly what we are about to do!)
⟨True, False ∣ True ∧ False = False, True ∧ False = True, False ∧ False = False, True ∧ False = False⟩
> boolAnd = [ ([True,True], [True])
> , ([True, False], [False])
> , ([False, True], [False])
> , ([False, False], [False]) ]In this case, the equations are just the definition for &&. Another monoid you’ve certainly seen as a programmer is the free monoid over X, which looks like this:
⟨X ∣ ⟩
> freeMonoid = []In other words, it is just lists of elements of X since there are no rules for manipulating the words. The List monad is intimately related to this monoid.
Another good example is the following – see if you can figure out what it represents before going on.
⟨x ∣ xn = e⟩
Yes, it is a presentation for the monoid (in fact, group) Zn, the integers mod n. You are intended to interpret the group operation as addition modulo n, x as 1, and e as the identity 0, hence xn is really n. Of course, the abstractness of the presentation meshes well with this group’s other name, the “cyclic group of order n“.
So, formalism is great fun and all, but sane folk prefer for computers to deal with it if possible. Our goal is to decide whether two words are equal according to the identities in the presentation. In general, this is undecidable, see
Here are some more example presentations for groups in Haskell, so I can use them. They are mostly harvested from http://en.wikipedia.org/wiki/Group_presentation and http://en.wikipedia.org/wiki/Knuth-Bendix_completion_algorithm
The cyclic group of order n, as above:
> cyclic n = [ (take n (repeat 'x'),"") ]The dihedral group of order 2n:
> dihedral n = [ (take n (repeat 'r'),"")
> , ("ff", "")
> , ("rfrf", "") ]The basic thing we are going to do is interpret equalities as rewriting rules. Everywhere the left-hand side appears, we insert the right-hand side. This function rewrites just once, if it finds an opportunity. I’m not going to even try for efficiency, since I get such a kick out of writing these pithy little Haskell functions.
> rewrite :: Eq a => Relation a -> Word a -> Word a
> rewrite _ [] = []
> rewrite rel@(lhs,rhs) word@(x:rest) = maybe (x:rewrite rel rest) ((rhs ++) . snd)
> maybeRewritten
> where maybeRewritten = find ((lhs ==) . fst) (zip (inits word) (tails word))A natural way to check if two words are equal is to reduce them until they can reduce no further, and see if these normal forms are equal.
> reduce :: Eq a => Presentation a -> Word a -> Word a
> reduce pres word = if word' == word then word else reduce pres word'
> where word' = foldr rewrite word presThis function fully reduces a word, assuming the presentation has “good” properties like always making words smaller according to a well-founded ordering. To make sure of this, we can orient any relation according to such an ordering.
> shortlex :: Ord a => Word a -> Word a -> Ordering
> shortlex l1 l2 = if length l1 < length l2 then LT
> else if length l1 > length l2 then GT
> else lexical l1 l2
> where lexical [] [] = EQ
> lexical (x:xs) (y:ys) = case compare x y of
> EQ -> lexical xs ys
> other -> other
>
> orient :: Ord a => Relation a -> Relation a
> orient (lhs,rhs) = case shortlex lhs rhs of
> LT -> (rhs, lhs)
> _ -> (lhs, rhs)But the results may be provably equal even though their normal forms are not, for example if I have this monoid
⟨x, y, z ∣ xy = yx = z⟩
> xyzExample = [ ("yx", "z")
> , ("xy", "z") ]I know that "xz" == "zx" but I cannot obviously prove it
*Main> reduce xyzExample “xz”
“xz”
*Main> reduce xyzExample “zx”
“zx”
because the proof goes through xz = xyx = zx. Knuth calls these “critical pairs” and they, in some sense, represent the point in a proof where someone had to be more clever than just cranking on the rules. But just to preview how completion works,
*Main> reduce (complete xyzExample) “xz”
“xz”
*Main> reduce (complete xyzExample) “zx”
“xz”
Voila!
We’ll also want to reduce relations and presentations. For relations, this is just reducing both sides, and orienting for good measure.
> reduceRel :: Ord a => Presentation a -> Relation a -> Relation a
> reduceRel pres (lhs,rhs) = orient (reduce pres lhs, reduce pres rhs)To reduce a presentation, we reduce each relation with all the other relations. If the two sides reduce to the same word, then the relation was redundant and we can delete it.
> trivial :: Eq a => Relation a -> Bool
> trivial (x,y) = x == y -- Otherwise known as `uncurry (==)`
>
> redundant :: Ord a => Presentation a -> Relation a -> Bool
> redundant pres = trivial . reduceRel pres
>
> reducePres :: Ord a => Presentation a -> Presentation a
> reducePres pres = filter (not . trivial) (reduceP [] pres)
> where reduceP prior [] = prior
> reduceP prior (r:future) = let r' = reduceRel (prior++future) r
> in reduceP (r':prior) futureNow on to the Knuth-Bendix procedure. The primary idea is to find all the possible critical pairs as described above, and to make new rewrite rules so they aren’t critical anymore. In other terminology, we look for exceptions to local confluence, and patch them up.
First, partitions is a list of ways to split a word into two nonempty parts.
> partitions :: Word a -> [(Word a, Word a)]
> partitions x = reverse . tail . reverse . tail $ zip (inits x) (tails x)Results looks like this:
*Main> partitions “abcde” [(“a”,”bcde”),(“ab”,”cde”),(“abc”,”de”),(“abcd”,”e”)]
Next, superpositions takes two words, and returns all the ways that the back of the first word could be the front of the second word.
> superpositions :: Eq a => Word a -> Word a -> [(Word a, Word a, Word a)]
> superpositions x y = map merge $ filter critical $ allPairs
> where critical ((a,b),(c,d)) = (b == c)
> merge ((a,b),(c,d)) = (a,b,d)
> allPairs = [(p1, p2) | p1 <- partitions x, p2 <- partitions y]*Main> superpositions “abb” “bbc” [(“a”,”bb”,”c”),(“ab”,”b”,”bc”)]
Then criticalPairs takes all the superpositions (x,y,z) where xy is reducible by one relation, and yz is reducible by the second, and returns the result of the aforementioned reductions. The last function, allCriticalPairs just filters these for inequivalent pairs.
> criticalPairs :: Eq a => Relation a -> Relation a -> [(Word a, Word a)]
> criticalPairs (l1,r1) (l2,r2) = map reduceSides (superpositions l1 l2)
> where reduceSides (x,y,z) = (r1 ++ z, x ++ r2)
>
> allCriticalPairs :: Ord a => Presentation a -> [(Word a, Word a)]
> allCriticalPairs pres = filter (not . redundant pres)
> $ concatMap (uncurry criticalPairs) rels
> where rels = [(r1,r2) | r1 <- pres, r2 <- pres]Just to save some redundant modification, we’ll assume the input presentation is reduced and oriented, and maintain that invariant ourselves with the help of this function. (Note how we run into the annoying aspect of Haskell where instances are global – so you can’t override the ordering on lists; there are good theoretical reasons for this annoyance but it still sucks!).
Then completion is pretty simple – just add the first non-reducible critical pair until there are no more.
> complete :: Ord a => Presentation a -> Presentation a
> complete pres = augment critPairs
> where augment [] = pres
> augment (x:_) = complete $ reducePres (x : pres)
> critPairs = map orient (allCriticalPairs pres)But this version of completion simplifies the presentation at every step, as per the descriptions of the algorithm I’ve seen – I obviously can’t do that if the result is infinite. The best I can think of is to track the finite number of relations I’ve already processed, and reduce each relation as I consider it according to those. And since I bet the order that generated rewrite rules are visited matters, I use the interleave function to make sure that all rewrite rules are eventually hit.
> quasicomplete :: Ord a => Presentation a -> Presentation a
> quasicomplete pres = augment [] pres
> where augment prior [] = []
> augment prior (x:xs) | redundant prior x = augment prior xs
> | otherwise = x':augment prior' rest
> where x' = reduceRel prior x
> prior' = reducePres (x:prior)
> rest = map (reduceRel prior') (interleave critPairs xs)
> critPairs = allCriticalPairs prior'> interleave :: [a] -> [a] -> [a]
> interleave [] ys = ys
> interleave xs [] = xs
> interleave (x:xs) ys = x:(interleave ys xs)And I need to directly test equality rather than reducing a relation and checking for triviality, since I don’t know when reduction is done.
> equiv :: Ord a => Presentation a -> Word a -> Word a -> Bool
> equiv pres w1 w2 = or (map equivPrefix (inits pres))
> where equivPrefix prefix = reduce prefix w1 == reduce prefix w2The above function does not give the same completions as the finite version, but it does seem to work. Here is a quickcheck property to test it. Since interesting presentations are probably hard to autogenerate, I just specialize it to the xyzExample.
> prop_quasiXYZ :: [XYZ] -> [XYZ] -> Bool
> prop_quasiXYZ xyz1 xyz2 =
> trivial (reduceRel (complete xyzExample) (w1,w2)) ==
> trivial (reduceRel (quasicomplete xyzExample) (w1,w2))
> where w1 = map unXYZ xyz1
> w2 = map unXYZ xyz2
>
> newtype XYZ = XYZ { unXYZ :: Char }
> instance Arbitrary XYZ where
> arbitrary = liftM XYZ $ oneof [return 'x', return 'y', return 'z']
> instance Show XYZ where
> show = show . unXYZAll seems well! Now here’s the example wikipedia uses for Knuth-Bendix:
> wikipediaExample = [ ("xxx", "")
> , ("yyy", "")
> , ("xyxyxy", "") ]Indeed, the finite completion algorith agrees with what Wikipedia says, and the following property passes lots of tests:
> prop_quasiWiki :: [XY] -> [XY] -> Bool
> prop_quasiWiki xy1 xy2 =
> trivial (reduceRel (complete wikipediaExample) (w1,w2)) ==
> trivial (reduceRel (quasicomplete wikipediaExample) (w1,w2))
> where w1 = map unXY xy1
> w2 = map unXY xy2
>
> newtype XY = XY { unXY :: Char }
> instance Arbitrary XY where
> arbitrary = liftM XY $ oneof [return 'x', return 'y']
> instance Show XY where
> show = show . unXYAnd the major test – I accidentally found out that my procedures don’t terminate for the dihedral groups greater than 3, so let’s make some tests of hand-checked equalities.
> d3 = quasicomplete (dihedral 3)> prop_d3 :: Bool
> prop_d3 = all (uncurry $ equiv d3) [ ("rrf", "fr")
> , ("frf", "rr")
> , ("frr", "rf")
> , ("f", "rfr")
> , ("rfrff", "rrfrr") ]If I were really fancy I’d take random walks on the rewrite rules and then see if completion could retrace those steps. But I’m not that fancy today!
Here’s my little pseudo-quickcheck main
> main = do mycheck ("prop_quasiXYZ", prop_quasiXYZ)
> mycheck ("prop_quasiWiki", prop_quasiWiki)
> mycheck ("prop_d3", prop_d3)
> where mycheck (name,prop) = do
> putStr (name ++ ": ")
> quickCheck prop